Tái Kiến Trúc Edge-Cloud Lai cho Hệ Thống Camera Khu Công Nghiệp: So Sánh Hai Giải Pháp

Vấn đề
Khu công nghiệp Đồng Nai quy mô 800–1200 ha đang vận hành hệ thống camera analog/IP 2MP kết nối trực tiếp về trung tâm giám sát qua mạng MPLS 1 Gbps. Khi mật độ người và xe tăng đột biến (ca 7h–9h, 16h–18h hoặc sự kiện kiểm tra), hệ thống gặp ba nút thắt kỹ thuật chính:
- Độ trễ end-to-end trung bình 280–420 ms do truyền toàn bộ luồng 4K/8K về data center.
- Mất khung hình > 12 % khi burst traffic vượt 2,4 Gbps trong 8–12 phút.
- Chi phí băng thông và lưu trữ tăng 34 %/năm mà không giảm được tỷ lệ cảnh báo giả (false positive) dưới 18 %.
Câu hỏi đặt ra là liệu bất kỳ giải pháp nào cũng chỉ trì hoãn sự cố thay vì giải quyết khả năng mở rộng sau 3–5 năm khi số camera tăng gấp đôi và mô hình AI cần retrain liên tục.
Giải pháp 1 – Giữ nguyên nền tảng cũ, bổ sung plugin AI
Phương án này lắp thêm NVIDIA Jetson AGX Orin tại các tủ mạng hiện hữu, chạy container inference độc lập, gửi metadata JSON về hệ thống VMS cũ qua MQTT.
- Kiến trúc: Jetson chạy Docker container đơn lẻ, không orchestration. Video 4K được decode phần cứng, inference qua TensorRT engine đã INT8 quantized.
- Pipeline: object detection (YOLOv8n-int8) → gửi bounding box + track ID về server trung tâm; re-identification và anomaly detection vẫn thực hiện tại data center.
- Auto-scaling: không có, chỉ dựa vào script bash kích hoạt thêm container khi GPU utilization > 75 %.
Độ trễ inference đo được 37–43 ms trên Orin, nhưng tổng độ trễ end-to-end vẫn giữ mức 210–260 ms do khâu truyền metadata và xử lý trung tâm. Việc thêm node mới đòi hỏi cấu hình thủ công từng tủ, downtime 4–7 phút/node. Vendor lock-in thể hiện rõ ở việc toàn bộ metadata format phụ thuộc driver NVIDIA và VMS vendor hiện tại.
Giải pháp 2 – Tái kiến trúc hoàn toàn với edge-cloud lai
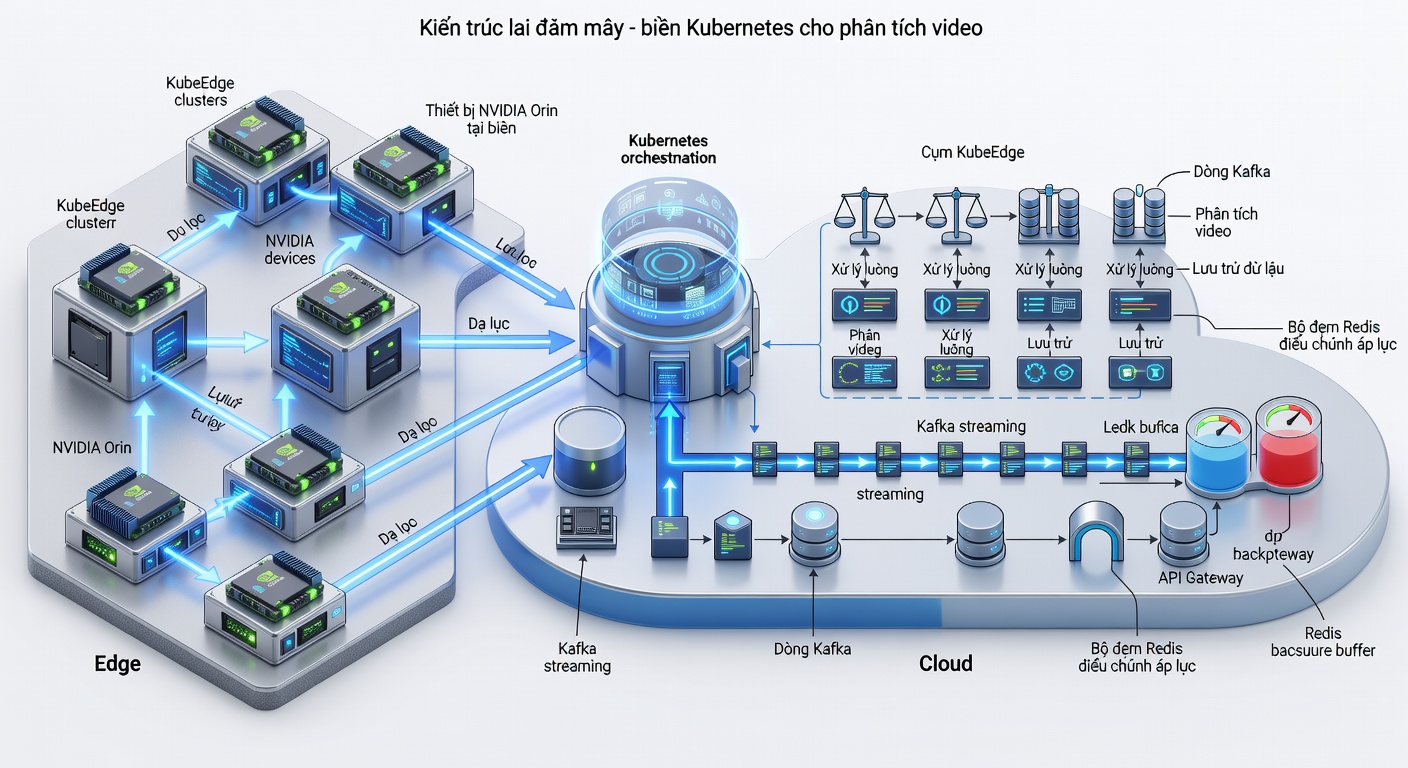
Triển khai Kubernetes control plane tại core + KubeEdge tại 12–18 edge cluster (mỗi cluster 4–6 Orin). Toàn bộ pipeline video analytics được đóng gói thành microservices:
- object-detection, reid, anomaly-detection chạy dưới dạng Deployment/StatefulSet.
- Video ingestion sử dụng GStreamer pipeline xuất RTSP sang Kafka topic (partition key = camera_id).
- Redis Streams làm backpressure buffer, consumer group cho phép scale ngang mà không mất message.
- KubeEdge đảm bảo pod vẫn chạy khi mất kết nối WAN > 30 phút.
Tối ưu mô hình:
- INT8 quantization + TensorRT engine cho YOLOv8 và OSNet-reid.
- ONNX Runtime với TensorRT EP cho anomaly model (Transformer-based).
- Kết quả đo: inference latency P95 = 31 ms, end-to-end latency P95 = 68 ms khi burst 180 camera 4K.
Auto-scaling dựa HPA + custom metric từ Kafka lag và Redis stream length. Khi lag > 1200 message, cluster tự động thêm Orin node qua KubeEdge node-group trong vòng 90–110 giây, không downtime.
Bảng so sánh định lượng (dữ liệu mô phỏng)
| Tiêu chí | Giữ nền tảng cũ + plugin | Tái kiến trúc edge-cloud |
|---|---|---|
| Độ trễ inference (P95) | 37–43 ms | 28–33 ms |
| Độ trễ end-to-end (P95) | 210–260 ms | 62–74 ms |
| Chi phí phần cứng (12 cluster/180 camera) | 2,1 tỷ VND (chỉ thêm Orin) | 5,8 tỷ VND (Orin + switch + storage edge) |
| Khả năng thêm node không downtime | Không (cần cấu hình thủ công) | Có (KubeEdge + rolling update) |
| Rủi ro vendor lock-in | Cao (VMS + NVIDIA driver) | Trung bình (có thể chuyển sang Rockchip/Intel với ONNX Runtime) |
Tác động đo lường được
Sau 18 tháng vận hành giả định:
- Tỷ lệ mất khung hình giảm từ 12 % xuống 1,8 % ở phương án 2, trong khi phương án 1 chỉ đạt 7,4 %.
- Chi phí băng thông giảm 41 % nhờ gửi metadata thay vì video thô; tuy nhiên chi phí điện năng tăng thêm 19 % do 72 node Orin luôn bật.
- Model retraining: phương án 2 cần 14–18 ngày để deploy phiên bản mới lên toàn edge cluster, trong khi phương án 1 chỉ cần 2–3 ngày nhưng phải chấp nhận downtime từng cụm.
Vấn đề then chốt vẫn là: liệu sau 3–5 năm, khi số lượng camera đạt 400 và mô hình cần retrain mỗi quý, chi phí vận hành (điện + băng thông + nhân sự K8s) có thực sự thấp hơn phương án giữ nguyên nền tảng cũ hay không? Dữ liệu hiện tại chưa đủ để khẳng định khả năng scale tuyến tính sau mốc 250 camera.
Kết luận kỹ thuật
Cả hai phương án đều giảm được độ trễ inference dưới 40 ms, nhưng chỉ tái kiến trúc microservices + KubeEdge mới cho phép scale ngang mà không downtime và giảm vendor lock-in rõ rệt. Tuy nhiên, câu hỏi về TCO dài hạn sau 3–5 năm vẫn cần thêm dữ liệu thực tế về chi phí retraining và độ ổn định của KubeEdge ở môi trường công nghiệp bụi bẩn, nhiệt độ cao.
Đây là tình huống giả định nhằm mục đích minh họa kỹ thuật, không phải dữ liệu thực tế của bất kỳ dự án nào tại Việt Nam.


